
Featured Content








Blog
Data Federation – DW Patterns – The Virtual Data Source
Following on from my last blog on data federation, the next data federation pattern I would like to discuss is a Data Warehouse Virtual Data Source pattern. This is as follows:
Pattern Description
This pattern uses virtual views of federated data to create virtual data source components for use in ETL processing. The purpose of this pattern is twofold. Firstly to protect ETL workflows from structural changes to operational data sources. Secondly to create re-usable virtual data source ‘components’ for accessing disintegrated master and transactional data. The virtual data source pattern effectively ‘ring fences’ just the data associated with a customer, or a product for example, meaning that ETL workflows can be built for customer data, product data, asset data, order data, etc. This helps ETL designers to create ETL jobs dedicated to a particular type of data, e.g. the customer ETL job, the product ETL job, the orders ETL job. Simplistic design of data consolidation workflows dedicated to a type of data allows these jobs to be re-used if the same data is needed elsewhere, e.g. customer data needed in two different data marts. It also guarantees that the same data is made available again and again via the same virtual data source
Pattern Diagram
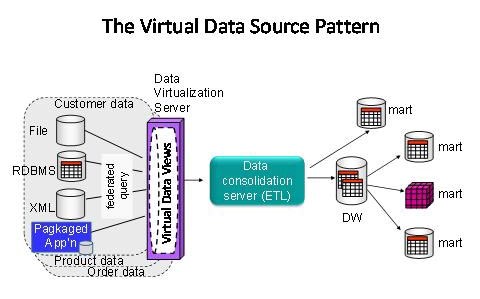
Pattern Example Use Case
Merger and acquisitions and new system releases often cause changes to operational systems data structures. This pattern can be used to shield ETL jobs that populate data warehouses and master data hubs from structural changes to source systems simply by changing the mappings in the virtual source views.
Reasons For Using It
Reasons for using this pattern include the ability to manage change more easily, lower ETL development and maintenance costs and modular design of data integration workflows associated with consolidating data.
Register for additional content
Register today for additional and exclusive content - informative research papers, product reviews, industry news.