
Featured Content








Blog
Data Federation – DW Patterns – Virtual Data Mart
Following on from my last blog on data federation, the next data federation pattern I would like to discuss is a Data Warehouse Virtual Data Mart pattern. This is as follows:
Pattern Description
This pattern uses data virtualisation to create one or more virtual data marts on top of a BI system thereby providing multiple summarised views of detailed historical data in a data warehouse. Different groups of users can then run ad hoc reports and analyses on these virtual data marts without interfering with each other’s analytical activity.
Pattern Diagram
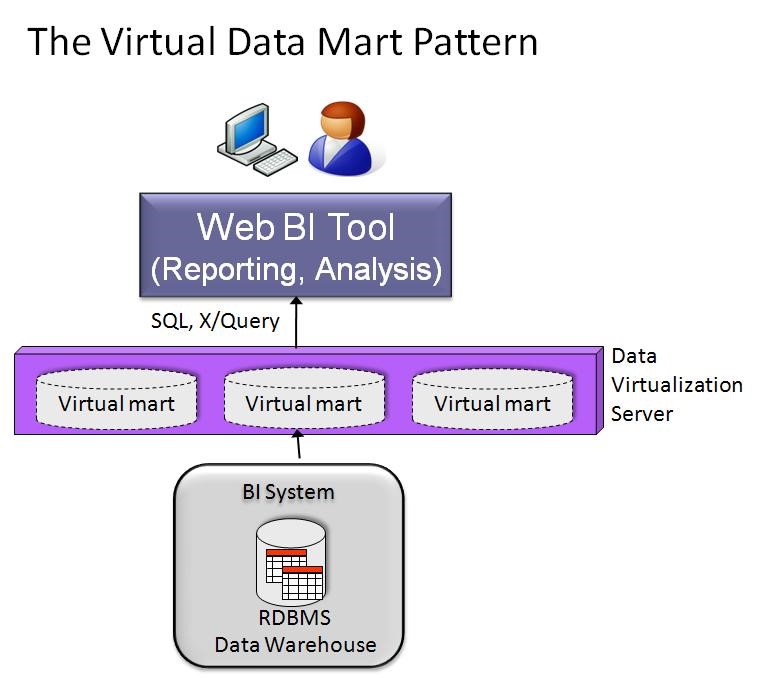
Pattern Example Use Case
Multiple ‘power user’ business analysts in the risk management department of a bank often need their own analytical environment to conduct specific in-depth analyses in order to create the best scoring and predictive models. This pattern facilitates the creation of multiple virtual data marts without the need to hold data in many different data stores
Reasons For Using It
Reduces the proliferation of data marts and also prevents inadvertent ‘personal’ ETL development by power users who have a tendency to want to extract their own data to create their own data marts. It is often the case that each power user wants a detailed subset of data from a data warehouse that overlaps with the data subsets required by other power users. This pattern avoids inadvertent inconsistent ETL processing on extracts of the same data by each and every power user. It also avoids the duplication of the same data in every data mart, improved power user business analyst productivity, reduces the time to create data marts and reduces the total cost of ownership.
Register for additional content
Register today for additional and exclusive content - informative research papers, product reviews, industry news.