




Blog
Has Informatica Raised the Bar on Hybrid Data and Application integration?
Over recent years the adoption of cloud computing has really gained momentum with more and more retailers, pharmaceuticals, telcos, financial services and just about every business voting to forgo the headache of managing complex hardware and software infrastructure themselves to spend more time trying to make use of applications, data, analytics and self-service BI tools running on top of cloud computing infrastructure to improve efficiency and competitiveness.
The promise of the cloud is very alluring – quick to get started, you only pay for what you use and cost and complexity of administering and managing the underlying infrastructure is taken care of by the cloud provider.
However for most, cloud adoption means living with a mix of on-premises and multiple cloud-based systems in a hybrid computing environment. The challenge is to ensure that processes, applications and data can still be integrated across cloud and on-premises systems either side of the corporate firewall.
To help with this requirement so called Integration Platform as a Service (iPaaS) software has emerged. This is software that runs in the cloud offering integration functionality “as a Service” to help integrate processes, applications and data. In that sense, iPaaS is multi-functional. It goes beyond Enterprise Service Bus (ESB) technology because its capabilities (should) cover data integration and data governance in addition to application integration. Also, integration can happen across multiple clouds as well as across cloud and on-premises systems. iPaaS also goes beyond ETL because it is capable of hybrid process and application integration. Therefore, it doesn’t fit neatly into the boxes that have appeared on many enterprise architecture diagrams produced over past years. The following diagram shows how iPaaS software, with its multi-functional capabilities, supports the integration of applications, data and things across one or more cloud and on-premises systems.
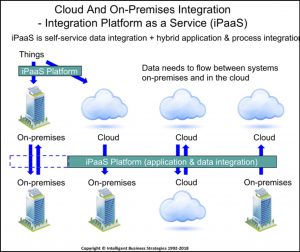
As you can see, its key role is in cloud-to-cloud and cloud-to-on premises integration.
iPasS Functional Requirements
If you were to look at it holistically, iPaaS functionality should include:
- Process and Application integration
- Cloud-to-cloud and cloud-to-on premises business process management (BPM) including business-to-business (B2B) process integration via EDI, XML and JSON
- Support for cloud-based application connectivity and integration via APIs
- Artificial intelligence to automatically discover and understand new data made available via these APIs
- Cloud-based application API management
- An API gateway to simplify access to complex applications and to iPaaS services
- Cloud-to-cloud and cloud-to-on premises application integration
- Application message routing, protocol and format translation
- Cloud-to-cloud and cloud-to-on-premises business activity monitoring (BAM) – real-time business analytics on process efficiency
- Data Integration – both for operational and analytical purposes
- Support for cloud based data store connectivity e.g. cloud-based Hadoop, NoSQL DBMSs, cloud Data Warehouses, cloud MDM systems etc.
- Support for on-premises data store connectivity
- Support for IoT and cloud based IoT data stores
- Managed file transfer between clouds and between cloud and on-premises systems
- Data integration to populate Cloud and On-premises data warehouses including
- support for data sources in multiple clouds
- Data integration to populate Cloud and On-premises MDM systems
- Data ingestion and data integration to prepare data for analysis on Cloud and On-premises Big Data systems
- Scalable data ingestion into cloud data stores from on-premises and other cloud systems
- Decoupling of data integration sources from targets so that data can be published by one or more source systems, integrated separately and subscribed to by multiple target systems
- Integrated metadata specifications governing process, application and data management
- Integration with an information catalog to make it possible to publish data, iPaaS workflows and templates etc., as findable, sharable and reusable assets that can be leveraged in any integration project
- Role based user interfaces to support IT integration architects, developers, and business users
- Business user productivity and simplification via wizards and pre-built integration templates that immediately deploy when given a connector
- Orchestration workflow to support data and application integration
- Exploiting cloud infrastructure as a Service (IaaS) and Platform as a Service (PaaS) resources via cloud specific APIs
- Push-down execution in multiple environments
- Policy based data and API security, privacy, auditing and monitoring
- Policy based dynamic auto-scaling
- Developer APIs to exploit iPaaS services
All of these capabilities should work together. Also, iPaaS functionality should be made available quickly, as and when needed, on any cloud (e.g. AWS, Microsoft Azure or Google Cloud) without your organisation having to worry about cloud specific APIs. That should be transparent. iPaaS software should also be elastic with the ability to make use of underlying cloud APIs to scale up compute and storage infrastructure resources when required and scale them down again when not. Ideally this elasticity should be policy driven to allow resources to be managed dynamically to minimise costs. This is, after all, pay as you use software that you want to make use of incrementally, and cost effectively.
Another way to look at iPaaS functionality is to think about operational versus analytical systems. In the case of operational systems, companies need iPaaS software to support internal and B2B process and application integration, cloud MDM and publish/subscribe data integration to synchronise operational master and transaction data across systems. In the case of analytical systems, data ingestion, and data integration for cloud data warehouses and cloud big data analytical systems are obvious requirements.
iPasS Use Cases
The aforementioned broad range of functionality means iPaaS software can be utilised in operational and analytical use cases. From an operational standpoint, it can be used for:
- Cloud to on-premises application and process integration
- B2B Cloud to on-premises process integration
- Migration data from on-premises operational applications to cloud based operational applications
- Integrating cloud-based data for use in on-premises and other cloud-based operational systems
- Integrating disparate master data to populate cloud-based MDM systems
- Synchronising master data from cloud-based MDM systems to other operational and analytical systems
From an analytics standpoint, it can be used for:
- Integrating disparate data from cloud and on-premises systems to populate cloud-based data warehouses
- Integrating data in cloud-based Hadoop systems or cloud storage (e.g. Amazon S3) to prepare the data for analysis
Informatica Intelligent Cloud Services
With growth in hybrid computing on the up, companies quickly reach the point where they need to make choices when it comes to iPaaS software and the recent winter release launch of Informatica’s iPaaS Intelligent Cloud Services (IICS) offering begs the question as to how well it stacks up given the above requirements? Let’s take a look.
Informatica has long been a leader in data management whether it be on-premises, in the cloud or both. Already a leader in iPaaS software, battling it out against vendors such as Dell, SnapLogic, Mulesoft, Jitterbit and many others, the new release of the micro-services based IICS (formerly Informatica Cloud Services) uses a common core platform and the Informatica CLAIRE™ metadata intelligence engine to bring together four Informatica cloud offerings. These are Informatica Integration Cloud, Data Quality & Governance Cloud, Master Data Management Cloud, and Data Security Cloud.
IICS can run on multiple clouds including Amazon AWS, Microsoft Azure and Google Cloud and provides integration capability to support both hybrid operational and analytical processing. In terms of integration between operational applications running on multiple clouds and on-premises data cetres, IICS supports:
- Connectivity to cloud applications including Salesforce, Oracle NetSuite, Workday, Marketo, Oracle JDEdwards Enterpriseone, Microsoft Dynamics, Oracle E-Business Suite and Eloqua plus many more with new connectors now available for Oracle HCM, Microsoft Dynamics 365 for Sales, SAP SuccessFactors, SAP Ariba, CallidusCloud Badgeville and CallidusCloud Litmos. The complete set of connectors is shown here
- Internal and B2B cloud application and process integration with AI-driven transformations on the B2B gateway
- API Management including
- Discovery of Swagger and WSDL based application APIs
- The ability to create and expose application APIs to enable application integration
- Policy-based API access management
- Monitoring of API security
- An API gateway to simplify access to complex applications
- Cloud MDM to integrate disparate master data (such as Customer data) across cloud and on-premises operational systems and synchronise ‘downstream’ systems in the same hybrid environment
- Pre-built integration templates to speed up integration across multiple cloud based and on-premises operational systems
- Cloud data quality and integration to ensure trusted data flow management between systems
- A cloud data integration hub to eliminate point-to-point application complexity and ‘integration spaghetti’ by replacing it with a publish and subscribe data integration hub so that data is integrated once and used by many
In terms of cloud based analytical systems, IICS supports:
- Data integration to populate cloud based Data Warehouse analytical databases such as Snowflake, Amazon Redshift, Microsoft Azure SQL Data Warehouse and Google Big Query
- Data integration on cloud big data platforms such as Amazon EMR, Microsoft Azure HDInsight and Hortonworks (on several clouds)
- Cloud-based data lake storage in Amazon S3 and Microsoft Azure Data Lake store
- Popular data formats found in data lakes and Hadoop systems such as Avro, Parquet and JSON
- A new mass ingestion capability to enable customers to transfer data in a flat file format from on-premises systems to Amazon S3 data stores and Amazon Redshift data warehouses in the cloud using standard protocols – FTP, SFTP and FTPS. Ingestion tasks can be authored using a wizard-based approach and ingestion jobs and file granularity can both be monitored
- Change data capture
- Support for Complex File Adaptor capability to integrate IoT data and bring it in for analysis
- Intelligent Structure Discovery powered by CLAIRE™ to connect IoT with enterprise data
- Artificial intelligence using the Informatica CLAIRE™ engine to help discover data ingested into cloud based object stores and data in data sources feeding cloud based analytical systems
- Cloud MDM to provide master dimension data to cloud and on-premises data warehouses and cloud and on-premises based big data systems
- Metadata sharing between Informatica PowerCentre and IICS to re-use on-premises data warehouse transformations in the cloud (e.g. on cloud based data warehouses) and to ensure best practices are inherited by business users in the cloud. This can also help speed up migration of on-premises based data warehouses to cloud based data warehouses
In addition, Informatica is opening up IICS to be used by both developers (via APIs) and business users. To support the latter, IICS includes several pre-built templates to improve productivity and simplify development. The templates include pre-built logic covering data preparation, cleansing and data warehousing. Also, companies can create their own templates, allowing IT to ensure that templates shared internally not only provide reusability but also represent best practice design and governance. Templates can also be published to Informatica Marketplace.
One of the other challenges with data management in a hybrid computing environment is keeping things organised. This is important both in terms of integration of operational applications and processes as well as in data integration for cloud data warehouses, cloud MDM and cloud big data analytical systems. This is achieved by support for projects. With respect to analytical systems, we have already seen several vendors, including Informatica, and IBM do this by introducing the concept of projects into data management software. Informatica Intelligent Data Lake supports projects. We see it here again in IICS with projects and folders accessible via the IICS Explore user interface. Both help organise assets with respect to integration initiatives. Also, access security can be managed by setting role-based access controls on projects, folders and individual files.
However, it is disappointing that projects cannot be shared across different Informatica software products. For example, IICS and Informatica Intelligent Data Lake (IDL) can’t share the same project if a big data project is being implemented on the cloud. Informatica Enterprise Data Catalog (EDC) is able to see lineage across all data in cloud and on-premises data stores and EDC REST APIs do allow other products and applications to access and reuse that metadata. Also, there are EDC metadata connectors and scanners that collect metadata from IICS, PowerCenter (and other ETL tools), IDL, BI tools etc., that help users find objects as well as services. However these jobs/services need to be executed from their native environment
One thing I do like however is Informatica Cloud Integration Hub. There is no doubt that the number of changes to APIs inside the enterprise looks like child’s play compared to the rate at which application APIs change on applications running in the many different clouds out there. You can imagine the cost of maintaining point-to-point application integration across clouds and between cloud and on-premises systems when trying to keep pace with API changes. It would look like a tangled mess of spaghetti and would be complex and very costly to maintain. The answer to this problem is to shed the complexity and maintenance nightmare in favour of simplicity using a cloud-based publish and subscribe data integration hub. This allows data from any cloud application to be mapped to commonly defined data structures in the integration hub and from there it can be mapped to as many subscribers as required. This is exactly what Informatica has done in IICS with its Cloud Integration Hub and it makes lots of sense in my opinion. Add to this the automated intelligent discovery, parsing and mapping offered by CLAIRE™ AI & Machine Learning and it is a very attractive option. Informatica Cloud Integration Hub
- Saves cost on point-to-point connectivity by using pub/sub data propagation
- Expedites and simplifies connectivity using self- service accelerators and automated discovery
- Offers wizards to guide non- technical users in building quick integrations
Finally, on top of all of this IICS offers on-the-fly data masking and intelligent recommendations around sensitive data. Dynamic data masking on sensitive data during data entry, data ingestion and during data flow between applications as part of an integration is a key requirement now that regulations like GDPR are upon us.
Overall, although there is more to do to deepen the integration of Informatica products to seamlessly manage data across multiple data stores in a hybrid environment, the winter release of IICS is a major advance on iPaaS software. When you look at the scope of operational and analytical use cases supported and couple these with Informatica MDM, Big Data Management and Intelligent Data Lake, IICS extends the coverage to the cloud environment. IICS is especially attractive to those companies already using Informatica data integration, MDM and big data management software inside the enterprise. It will certainly keep Informatica at the top end of the leader board. I just feel that Informatica still has to clarify its message as to how all its software components and corresponding metadata fit together to manage data from end-to-end on both sides of the firewall.
If you want to know more about how to manage and govern data across Hadoop, Cloud Storage, MDM, Data Warehouses and NoSQL data stores please join me on my 2-day class, dates here or email us for details of on-site classes
Register for additional content
Register today for additional and exclusive content - informative research papers, product reviews, industry news.